PriorMDM: Human Motion Diffusion
as a Generative Prior
Abstract
In recent months, we witness a leap forward as denoising diffusion models were introduced to Motion Generation.
Yet, the main gap in this field remains the low availability of data. Furthermore, the expensive acquisition process of motion biases the already modest data
towards short single-person sequences. With such a shortage, more elaborate generative tasks are left behind.
In this paper, we show that this gap can be mitigated using a pre-trained diffusion-based model as a generative prior.
We demonstrate the prior is effective for fine-tuning, in a few-, and even a zero-shot manner.
For the zero-shot setting, we tackle the challenge of long sequence generation. We introduce DoubleTake, an inference-time method with which
we demonstrate up to 10-minute long animations of prompted intervals and their meaningful and controlled transition, using the prior that was trained for
10-second generations.
For the few-shot setting, we consider two-person generation.
Using two fixed priors and as few as a dozen training examples, we learn a slim communication block, ComMDM,
to infuse interaction between the two resulting motions.
Finally, using fine-tuning, we train the prior to semantically complete motions from a single prescribed joint.
Then, we use our DiffusionBlending to blend a few such models into a single one that responds well to the combination of the individual control signals,
enabling fine-grained joint- and trajectory-level control and editing.
Using an off-the-shelf state-of-the-art (SOTA) motion diffusion model as a prior,
we evaluate our approach for the three mentioned cases.
Compared to SOTA methods, the DoubleTake approach demonstrates better quality scores for the intervals themselves and significantly better scores
for the transitions between them. Through a user study, we show our communication block scores better quality and interaction levels compared to a
SOTA model dedicated to the multi-person task. Our DiffusionBlending outperforms the motion inpainting approach over four different combinations of joints.
DoubleTake algorithm - Long motions
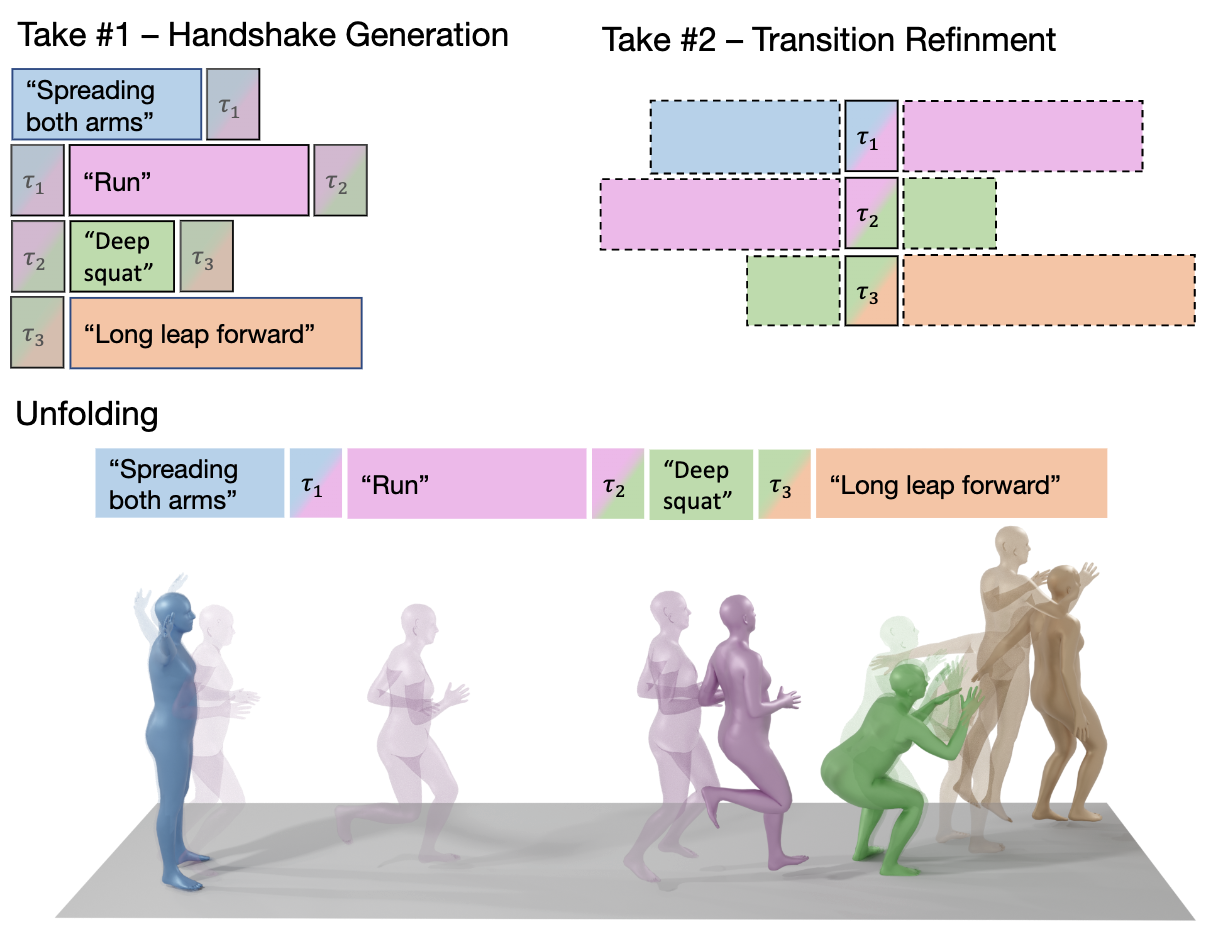
Our DoubleTake method (above) enables the efficient generation of long motion sequences in a zero-shot manner. Using it,
we demonstrate 10-minute long fluent motions that were generated using a model that was trained only on ~10 second long sequences.
In addition, instead of a global textual condition,
DoubleTake controls each motion interval using a different text condition while maintaining realistic transitions between intervals.
This result is fairly surprising considering that such transitions were not explicitly annotated in the training data.
DoubleTake consists of two phases - in the first step, each motion is generated conditioned on a text prompt while being aware of the context of neighboring motions,
all generated simultaneously in a single batch.
Then, the second take exploits the denoising process to refine transitions to better match the intervals.
The following long motion was generated with DoubleTake in a single diffusion batch. Orange frames are the textually controlled interval, and the blue/purple frames are the transitions between them.
DoubleTake - Results
Lighter frames represent transition between intervals.
DoubleTake vs. TEACH model
The followings are side-by-side views of our DoubleTake approach compared to TEACH[Athanasiou et al. 2022] that was dedicatedly learned for this task. Both got the same texts and sequence lengths to be generated.
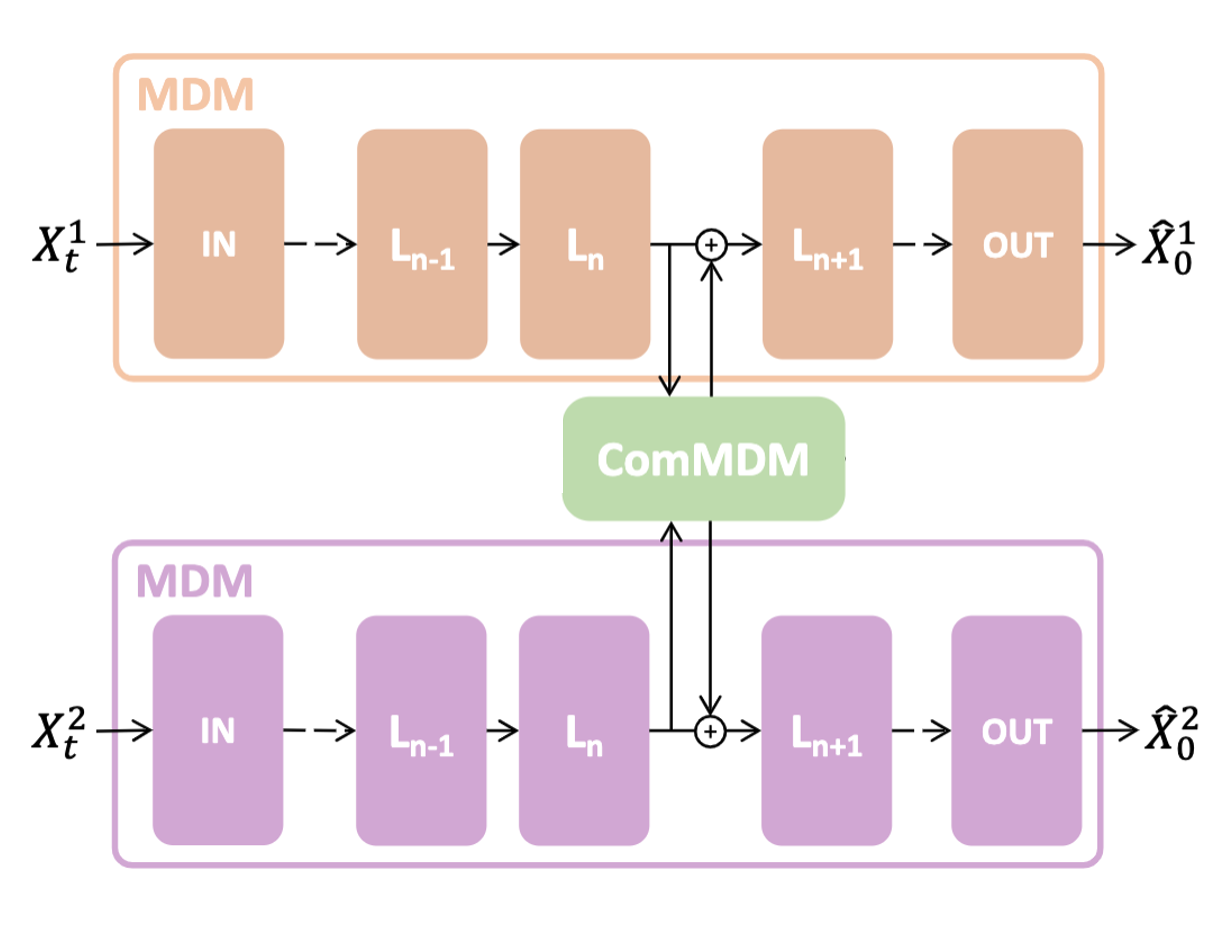
ComMDM - Two-person motion generation
For the few-shot setting, we enable textually driven two-person motion generation for the first time. We exploit MDM as a motion prior for learning two-person motion generation using only as few as a dozen training examples. We observe that in order to learn human interactions, we only need to enable fixed prior models to communicate with each other through the diffusion process. Hence, we learn a slim communication block, ComMDM, that passes a communication signal between the two frozen priors through the transformer's intermediate activation maps.
Two-person - Text-to-Motion Generation
The followings are text-to-motion generations by our ComMDM model, learned with only 14 motion examples. The texts are unseen by the model but the interactions are fairly limited to those seen during training. Different color defines different character, both are generated simultaneously.
“A Capoeira practice. One is kicking and the other is avoiding the kick.”
“A Capoeira practice. One is kicking and the other is avoiding the kick.”
“The two people are playing basketball, one with the ball the other is defending.”
“The two people are playing basketball, one with the ball the other is defending.”
Two-person - Prefix Completions
The followings are side-by-side views of our ComMDM approach compared to MRT[Wang et al. 2021] that was dedicatedly learned for this task. Both got the same motion prefixes to be competed.
Blue is input prefix and orange/red is the generated completions by each model.
Fine-Tuned Motion Control
We observe that the motion inpainting process suggested by MDM[Tevet et al. 2022] does not extend well to more elaborate yet important motion tasks such as trajectory and end-effector tracking.
We show that fine-tuning the prior for this task yields semantic and accurate control using even just a single end-effector.
We further introduce the DiffusionBlending technique that generalizes classifier-free guidance to blend between different fine-tuned models and create any cross combination of keypoints control on the generated motion.
This enables surgical control for human motion that comprises a key capability for any animation system.
The followings are side-by-side comparison of our fine-tuned MDM and DiffusionBlending (models with + sign) to MDM motion inpainting.